

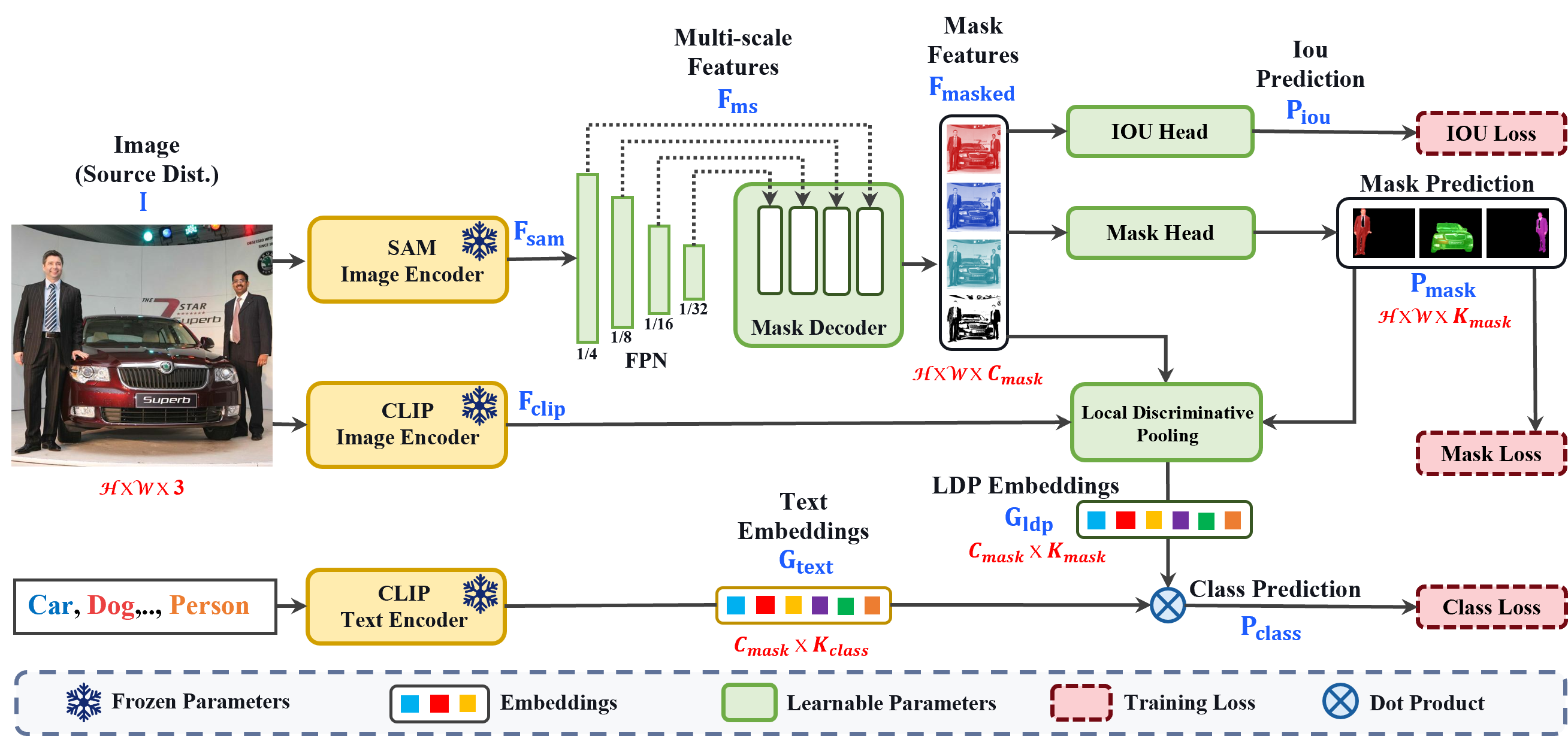
 Overview of our PosSAM training pipeline. We first encode the input image
using the SAM backbone to extract spatially rich features, which are processed through
a Feature Pyramid Network to obtain hierarchical multi-scale features decoded to form
mask features and predict class-agnostic masks. Concurrently, we train an IoU predictor
for each mask to measure its quality. For classification, using our proposed LDP module we enhance
discriminative CLIP features with class-agnostic SAM features for an unbiased OV classification. These LDP features are then classified by a standard open-vocabulary
supervision with ground truth category labels derived from the CLIP text encoder.
Overview of our PosSAM training pipeline. We first encode the input image
using the SAM backbone to extract spatially rich features, which are processed through
a Feature Pyramid Network to obtain hierarchical multi-scale features decoded to form
mask features and predict class-agnostic masks. Concurrently, we train an IoU predictor
for each mask to measure its quality. For classification, using our proposed LDP module we enhance
discriminative CLIP features with class-agnostic SAM features for an unbiased OV classification. These LDP features are then classified by a standard open-vocabulary
supervision with ground truth category labels derived from the CLIP text encoder.
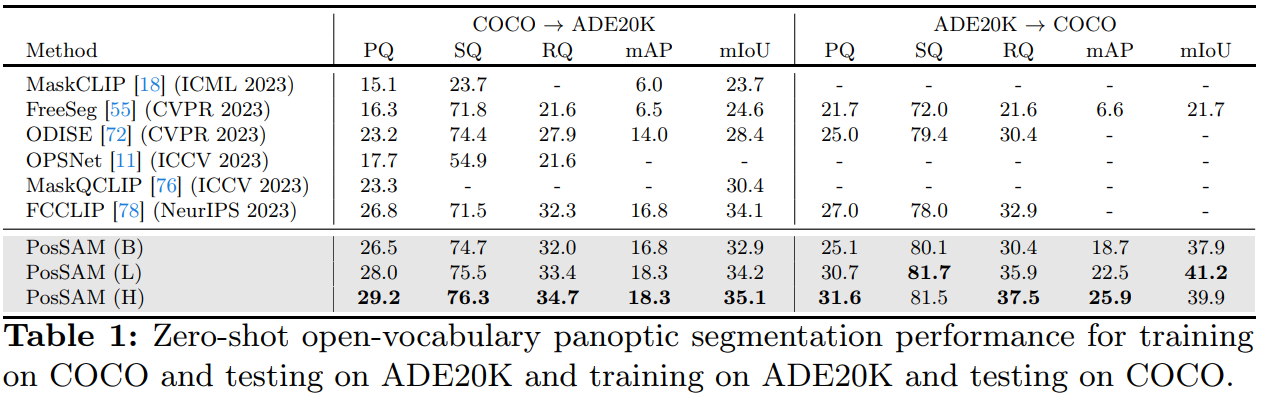
 Zero-shot panoptic segmentation capability from COCO to ADE20K on unseen classes. This figure shows comparison with recent SOTA approaches. Only novel classes are shown. We can observe that PosSAM has the ability to accurately
segment objects that are never seen before such as paintings, dishwashers, exhaust, showing advantages over other SOTA methods.
Zero-shot panoptic segmentation capability from COCO to ADE20K on unseen classes. This figure shows comparison with recent SOTA approaches. Only novel classes are shown. We can observe that PosSAM has the ability to accurately
segment objects that are never seen before such as paintings, dishwashers, exhaust, showing advantages over other SOTA methods.
@article{vs2024possam,
title={PosSAM: Panoptic Open-vocabulary Segment Anything},
author={VS, Vibashan and Borse, Shubhankar and Park, Hyojin and Das, Debasmit and Patel, Vishal and Hayat, Munawar and Porikli, Fatih},
journal={arXiv preprint arXiv:2403.09620},
year={2024}
}